Collection structure
An NFT can be unique, like an exclusive work of art, or it can be part of a series, like playing cards, where the only thing that changes in the assets of the same edition is the order in which they have been minted. For the latter case, AtomicAssets offers the possibility of configuring a "template" to be able to issue more copies of the assets every time we need more units, infinitely or until we reach a previously established quantity, as we will see. For example, we could have a template for the game object "Silent Sword of Oblivion", with all its attributes already defined: the image, its name, its description, etc.
But as we will have other types of assets in the game, we can create different templates whose structure will be identical but not their content. This structure can be defined in what AtomicAssets calls "schemas". Schemas define what kind of data the templates we generate from them will contain.
Perhaps our set, or collection, has assets that we want to differentiate from each other, such as character cards, spell cards, ability cards, weapon cards and armour cards, so each of those categories will be defined in its own schema and, all together, will form what AtomicAssets calls a "collection", which will serve to define a name and description for the whole set, as well as serving as a general container for all the assets created under it.
In short, AtomicAssets organises the collection set in different levels of subsets:
Collection -> Schemas -> Templates -> NFTs.
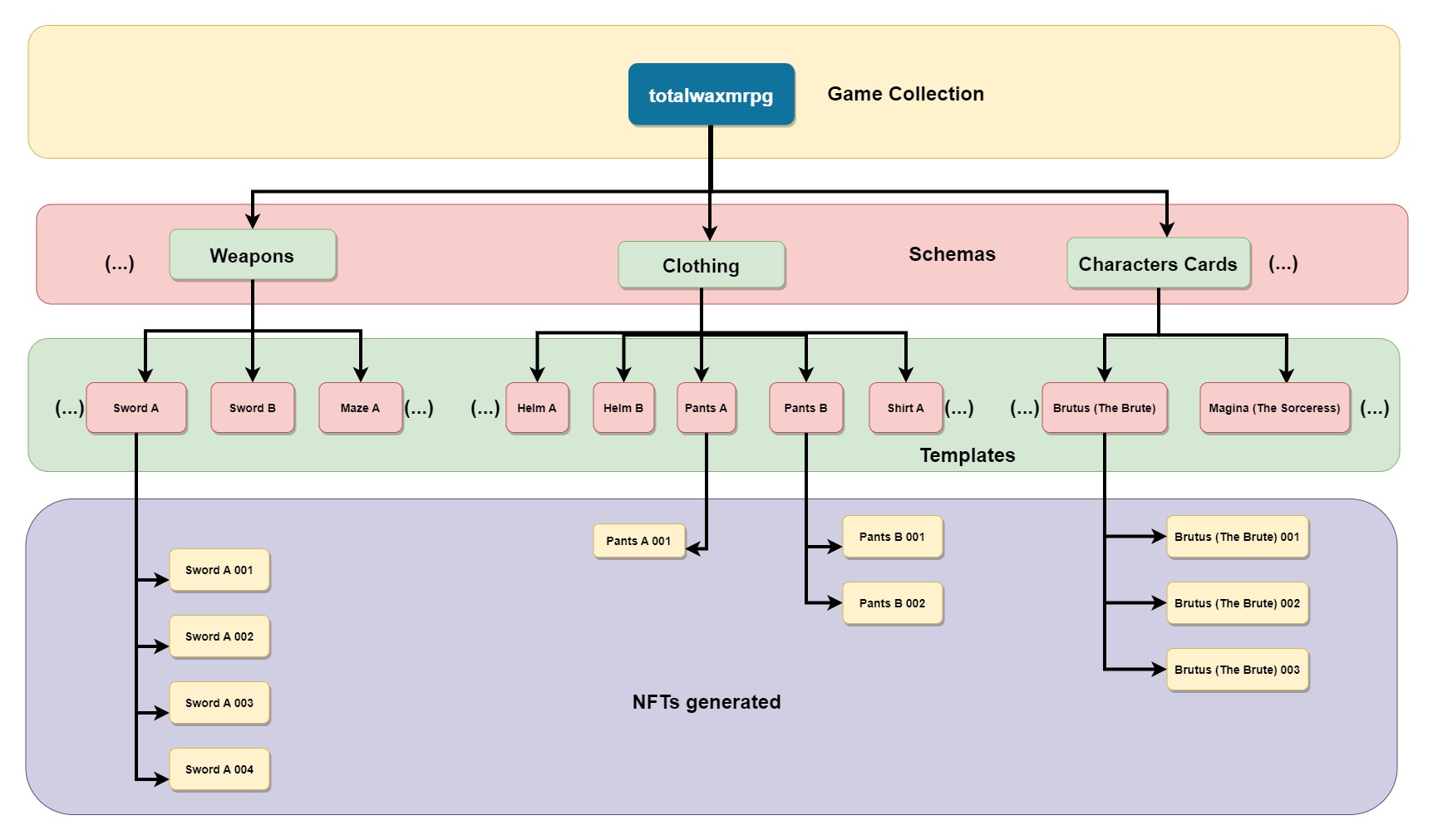
Collection
A collection is defined with the following information:
- Collection name.
- Author or owner.
- Description and identification data.
- List of authorised accounts.
- List of accounts that will receive notifications.
- Royalty fee for trading in markets.
The description and identification data are entered according to the following structure:
[
{ "name": "name","type": "string" },
{ "name": "img", "type": "ipfs" },
{ "name": "description", "type": "string" },
{ "name": "url", "type": "string" },
{ "name": "images", "type": "string" },
{ "name": "socials", "type": "string" },
{ "name": "creator_info", "type": "string" }
]If we create the collection from an interface like https://waxblock.io we will have to fill in this data entry:
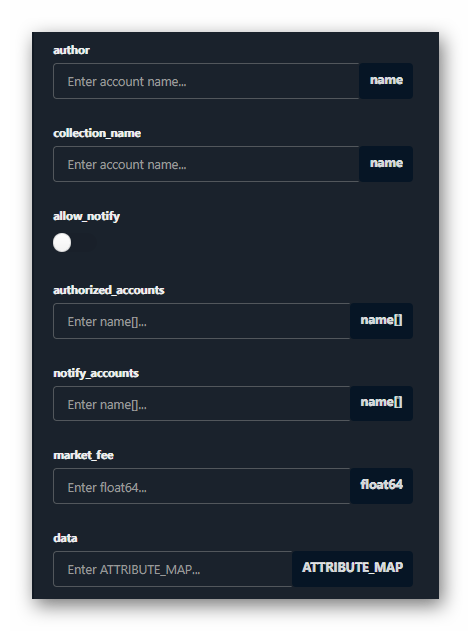
An example of the information accepted in the "data" field is shown below.
data:
{"key":"name","value":["string","mycollection"]}
{"key":"img","value":["string","QmXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"]}
{"key":"description","value":["string","This is a collection created for testing"]}
{"key":"url","value":["string","https://mysite.io"]}
{"key":"socials","value":["string","{
\"twitter\":\"mytwitter\",
\"facebook\":\"myfacebook\",
\"medium\":\"mymedium\",
\"github\":\"mygithub\",
\"telegram\":\"mytelegram\",
\"youtube\":\"myyoutube\",
\"discord\":\"\mydiscord"}"]}
{"key":"creator_info","value":["string","{
\"address\":\"\",
\"company\":\"\",
\"name\":\"\",
\"registration_number\":\"\"}"]}
{"key":"images","value":["string","{\
"banner_1920x500\":\"QmQtXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX\",
\"logo_512x512\":\"\"}"]}Schema
The schema serves two main functions; to group the NFTs in the collection according to certain common attributes and to declare the data types that we can use when creating the NFTs.
When declaring the data structure we will use vectors of FORMAT; tuples formed by a name and a data type.
Once a data schema has been created, it is possible to add more data to it but existing data can no longer be deleted or modified (Tip: it is also not mandatory to use all the declared data in the templates).
Template
The template is the mould with which all assets of the same type will be minted. The template is where the information that will be available in an NFT such as the name, the image URL (preferably IPFS), the description, etc. is declared. Thanks to this, it is not necessary to repeat the information over and over again in every NFT that is minted. To know the name, description or any other field of an NFT, it is only necessary to access the content of that attribute declared in the template.
Immutable data are stored in the template but mutable data, specific to each NFT unit, are stored in the same NFT to which they belong and, if they exist, they will increase the RAM memory consumed. :::