WAX Hyperion Full History requires a substantial amount of data to be Indexed from the WAX Blockchain, whether on Mainnet or Testnet.
The amount of time it takes to accomplish a full index, as well as the stability of the indexing process (especially the initial bulk indexing) can be influenced by tuning the Hyperion Indexer Scaling settings.
This next sub-article in the series will describe the various wax.config.json indexer scaling settings, walk through the flow of how data is indexed and finally provide suggestions on how to tune for your specific deployment.
EOS RIO have an excellent Hyperion Documentation Repository including details on how to run their Hyperion Full History product, however this article will expand on their current documentation.
Once again this Technical How To series will cover some of EOS RIO’s same content and will add operational nuances from a practical stand point and our experience.
Learn more about EOS RIO Hyperion

This article has been updated to reflect the current Hyperion deployment in December 2024.
WAX Hyperion Full History Indexer Scaling
The WAX Hyperion Indexer scaling settings are located in the wax.config.json file.
Out the box Hyperion includes an example.config.json file that already has conservative base settings from where to start.
> nano ~/hyperion-history-api/chain/wax.config.json
"scaling": {
"readers": 1,
"ds_queues": 1,
"ds_threads": 1,
"ds_pool_size": 1,
"indexing_queues": 1,
"ad_idx_queues": 1,
"dyn_idx_queues": 1,
"max_autoscale": 4,
"batch_size": 5000,
"resume_trigger": 5000,
"auto_scale_trigger": 20000,
"block_queue_limit": 10000,
"max_queue_limit": 100000,
"routing_mode": "round_robin",
"polling_interval": 10000
},These settings can be granularly adjusted to add more readers, queues, pools etc. often with positive performance results. However more is not always better and can end up overwhelming your hardware, network, database and deployment in general causing poor performance and crashes.
Indexer Scaling Settings
readers:
The number of websocket connections to the SHIP node.
ds_queues:
The number of deserialiser queues feeding the deserialiser threads.
ds_threads:
The number of deserialiser process threads to use deserialising actions from the received data.
ds_pool_size:
The number of deserialiser pool queues to use for stacking the deserialised actions.
indexing_queues:
The number of indexing queues to use for data pre indexer process.
ad_idx_queues:
The number of indexing queues to use for actions and deltas data pre indexer process.
dyn_idx_queues:
The number of indexing queues to use for dynamic data pre indexer process.
max_autoscale:
The maximum number of readers to autoscale to for the indexer process that sends data to Elasticsearch.
batch_size:
This is the queue limit size in RabbitMQ.
resume_trigger:
Defines the queue size that will allow the worker to resume consuming after it has being stopped by max_queue_limit or block_queue_limit
auto_scale_trigger:
The number of items in the indexer process queue to trigger another reader.
block_queue_limit:
Maximum queue size allowed for stage 1 queues (blocks)
max_queue_limit:
Maximum queue size for any other queue
If any of these queues are above the limit, the readers will be paused. For example, if you have a ds_pool queue above limit, all readers will stop receiving data from the SHIP node, except for the live reader.
The ds_pool size will keep growing until there are no more blocks in the blocks queue. When the size is below the resume_trigger the readers will resume.
routing_mode:
The routing method used for allocating deserialised data into a ds_pool queue. heatmap and round-robin are configurable.
polling_interval:
Used to define how frequently (in milliseconds) queue size checks are made. 10 seconds is the default however there are some cases that it might be useful to lower that time and reduce the queue sizes, so that you avoid RabbitMQ using too much memory.
You may have noticed that these settings don’t directly match what you may be seeing in the RabbitMQ Dashboard
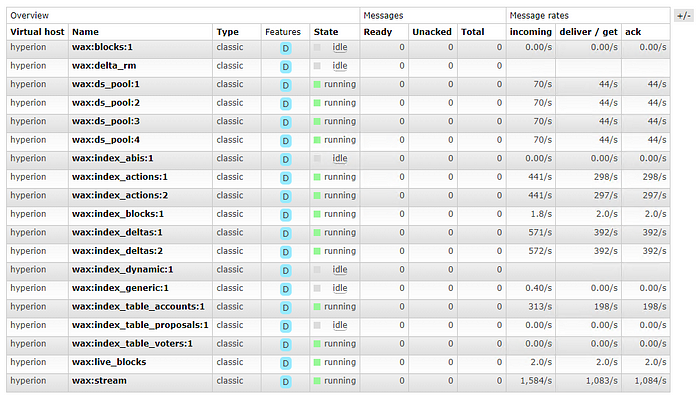
Understanding how the RabbitMQ maps to Indexer Scaling settings can be very helpful in determining where there may be a performance issue or a backlog of data in the queue. Below are the direct mappings:
:blocks: -> ds_queues
:ds_pool: -> ds_pool_size
:index_actions: -> ad_idx_queues
:index_blocks: , :index_deltas: , :index_generic: , :index_table_accounts: , :index_table_proposals: -> indexing_queues
:index_dynamic: -> dyn_idx_queues
Data Indexing Flow
The high level flow of how SHIP data moves through the Hyperion Indexing Process to Elasticsearch can be summerised as below:
- Readers acquire data from the SHIP node via websocket.
- This data will be distributed round-robin to all ds_queues.
- Data in the ds_queues is consumed by ds_threads and deserialised.
- These deserialised actions are then placed in the ds_pool queue based on their contract usage.
- Actions are then sent to the respective indexing_queues, ad_idx_queues or ad_idx_queues.
- These indexing queues are then ingested by the indexer processes and sent to Elasticsearch. Indexer processes are automatically launched if needed until the max_autoscale is reached.
Suggestions
Here are a few suggestions on starting your indexer for the first time and then cranking it up to take advantage of your specific infrastructure:
- Run Elasticsearch on hardware separate to RabbitMQ, Redis and Hyperion.
- The №1 RabbitMQ rule is to keep all queues as small as possible.
- Keep the settings default when first starting, be sure all software components and infrastructure along the indexing path are working as expected within thresholds.
- Increase number of readers if your SHIP server can handle it (Check your SHIP server health), most of the time a SHIP server on LAN only needs a single reader configured in Hyperion. Increase this number if the SHIP server is remote.
- Start with slowly upping the queues, for the most part 1 or 2 clicks in the below ratio is all you need.
"scaling": {
"readers": 1,
"ds_queues": 2,
"ds_threads": 2,
"ds_pool_size": 6,
"indexing_queues": 2,
"ad_idx_queues": 2,
"dyn_idx_queues": 2,
"max_autoscale": 4,
"batch_size": 5000,
"resume_trigger": 5000,
"auto_scale_trigger": 20000,
"block_queue_limit": 10000,
"max_queue_limit": 100000,
"routing_mode": "round_robin",
"polling_interval": 10000
},- To date we haven’t needed to change of the default scaling
- The current recommendation is to leave the routing mode on
round_robinand to avoidheatmap(heatmap mode is currently experimental and shouldn’t be use in production) - ds_queues, ds_threads**,** ds_pool_size have a direct effect on the resources needed by RabbitMQ (Monitor any queue backlog or hardware utilisation in RabbitMQ)
- indexing_queues, ad_idx_queues, dyn_idx_queues and the scaling settings, have a direct effect on the resources needed by Elasticsearch (Monitor Elasticsearch hardware utilisation)
A special Thank-You to Igor Lins e Silva (EOS RIO — Head of Technology) for his assistance in compiling this guide.
Update: The EOS RIO Team are experimenting with non-durable queues, meaning RabbitMQ will keep all data in-memory without ever writing to disk. RabbitMQ currently stores the queue data on disk to prevent errors on restart. Since there is no risk of losing onchain data there should be a performance benefit.
These WAX Developer Technical Guides are created using source material from the EOSphere WAX Technical How To Series
Be sure to ask any questions in the EOSphere Telegram